3D Reconstruction and Perception of People
NOTE: For more information and full list of publications visit the Real Virtual Humans site: https://virtualhumans.mpi-inf.mpg.de
Humans are incredibly good at perceiving people from visual data. Without even thinking about it, we quickly perceive the body shape, posture, facial expressions and clothing of other people. We believe all these details are crucial to understand humans from visual data, and to have natural communication.
Computer Vision methods in this area have seen a lot of progress thanks to the availability of large scale datasets with crowd sourced 2D annotations such as 2D joints and segmentation masks. Deep learning methods can predict such annotations because they are very effective at recognizing patterns. However, humans are far more complex than 2D joints or segmentation masks and unfortunately it is practically impossible to manually annotate in images full 3D geometry, human motion or clothing.
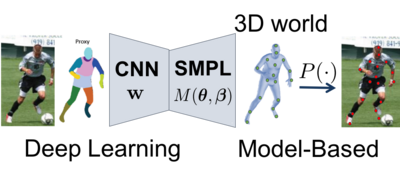
Our approach to this problem is to infer and learn a powerful representation of people in 3D space. Intuitively, such representation encodes the machine mental model of people. Given an image, the inference algorithms should predict the full detail in 3D, which should be consistent with learned 3D human shape priors and its projection should overlap with the image observations. This opens the door for semi-supervised learning because unlabeled images alone can be used to infer properties about the 3D world.
Following this paradigm, we introduced methods to reconstruct 3D human shape and pose from images, human shape and clothing from videos, and non-rigid deformations from video.