Object Recognition and Scene Understanding

Learning Non-Maximum Suppression
Object detectors have hugely profited from moving towards an end-to-end learning paradigm: proposals, features, and the classifier becoming one neural network improved results two-fold on general object detection. One indispensable component is non-maximum suppression (NMS), a post-processing algorithm responsible for merging all detections that belong to the same object. We propose a new network architecture designed to perform non-maximum suppression (NMS), using only boxes and their score. We report experiments for person detection on PETS and for general object categories on the COCO dataset.

Cityscapes Dataset
We present a new large-scale dataset that contains a diverse set of stereo video sequences recorded in street scenes from 50 different cities, with high quality pixel-level annotations of 5000 frames in addition to a larger set of weakly annotated frames. The dataset is thus an order of magnitude larger than similar previous attempts. Details on annotated classes, example images and more are available at this webpage.

What makes for effective detection proposals?
Detection proposals allow to avoid exhaustive sliding window search across images, while keeping high detection quality. We provide an in depth analysis of proposal methods regarding recall, repeatability, and impact on DPM, R-CNN, and Fast R-CNN detector performance.
We introduce a novel metric, the average recall (AR), which rewards both high recall and good localisation and correlates surprisingly well with detector performance. Our findings show common strengths and weaknesses of existing methods, and provide insights and metrics for selecting and tuning proposal methods.
See the Difference: Direct Pre-Image Reconstruction and Pose Estimation by Differentiating HOG
We exploit the piece-wise differentiability of HOG descriptor to facilitate differentiable vision pipelines. We present our implementation of ∇HOG based on the auto-differentiation toolbox Chumpy and show applications to pre-image visualization and pose estimation which extends the existing differentiable renderer OpenDR pipeline.

Object Disambiguation for Augmented Reality Applications
In this project we propose a novel object recognition system that fuses state-of-the-art 2D detection with 3D context. We focus on assisting a maintenance worker by providing an augmented reality overlay that identifies and disambiguates potentially repetitive machine parts. In addition, we provide an annotated dataset that can be used to quantify the success rate of a variety of 2D and 3D systems for object detection and disambiguation.
")
Scalable Multitask Representation Learning for Scene Classification
We propose a multitask learning approach (MTL-SDCA) which scales to high-dimensional image descriptors (Fisher Vector) and consistently outperforms the state of the art on the SUN397 scene classification benchmark with varying amounts of training data and varying K when classification performance is measured via top-K accuracy.

Learning Using Privileged Information: SVM+ and Weighted SVM
We relate the privileged information to importance weighting and show that the prior knowledge expressible with privileged features can also be encoded by instance weights.
Moreover, we argue that if there is vast amount of data available for model selection (e.g. a validation set), it can be used to learn instance weights that allow the Weighted SVM to outperform SVM+.

Learning Smooth Pooling Regions for Visual Recognition
In this project we have investigated the pooling stage in the Spatial Pyramid Matching (SPM) architectures. In order to preserve some spatial information, typically the SPM methods divide the image into sub-regions in a fixed manner according to some division template (for instance by splitting the image into 2-by-2 non-overlapping sub-regions), and next aggregate statistics separately over such sub-regions. In this work, we question such arbitrary division and propose a method that discriminatively learn the optimal division together with the classifier's parameters. Finally, we have shown experimentally that such optimized pooling stage boosts the overall accuracy in the visual recognition task and therefore cannot be left as an arbitrary choice.

Recognizing Materials from Virtual Examples
In this project, we investigate if and how appearance descriptors can be transferred from the virtual world to real examples. We study two popular appearance descriptors on the task of material categorization as it is a pure appearance-driven task. Beyond this initial study, we also investigate different approach of combining and adapting virtual and real data in order to bridge the gap between rendered and real-data. Our study is carried out using a new database of virtual materials MPI-VIPS that complements the existing KTH-TIPS material database.

MPII Multi-Kinect Dataset
In this project we explore the benefit of using multiple depth cameras (Microsoft Kinect) for object localization. We provide MPII Multi-Kinect Dataset, a novel dataset which is collected with four Kinect cameras simultaneously in a kitchen environment.
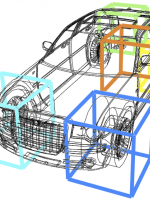
Teaching 3D Geometry to Deformable Part Models
State-of-the-art object detectors nowadays typically target 2D bounding box localization of objects in images. While this is sufficient for object detection itself, there are important computer vision problems like 3D scene understanding and autonomous driving which would benefit much more from object detector capable of outputing richer object hypotheses (viewpoints of objects, correspondences across views, fine-grained categories etc).
In this work we aim at narrowing the representational gap which exists between the standard object detector output and the ideal input of a high-level vision task, like 3D scene understanding.

Cross-Modal Stereo by Using Kinect
We complement the depth estimate within the Kinect by a cross-modal stereo path that we obtain from disparity matching between the included IR and RGB sensor of the Kinect. We investigate physical characteristics of the Kinect sensors: how the RGB channels can be combined optimally in order to mimic the image response of the IR sensor. Adapting RGB in frequency domain to mimic an IR image did not yield improved performance. We further propose a more general method that learns optimal filters for cross-modal stereo under projected patterns. Our combination method produces depth maps that include sufficient evidence for reflective and transparent objects, and preserves at the same time textureless objects, such as tables or a walls.

Image Warping For Face Recognition
In this project we develop novel image warping algorithms for full 2D pixel-grid deformations with application to face recognition. We propose several methods with different optimization complexity depending on the type of mutual dependencies between neighboring pixels in the image lattice. We evaluate the presented warping approaches on four challenging face recognition tasks in highly variable domains.
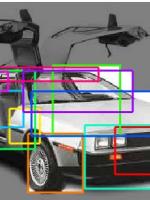
Addressing scalability in object recognition
While current object class recognition systems achieve remarkable recognition performance for individual classes, the simultaneous recognition of multiple classes remains a major challenge: building reliable object class models requires a sufficiently high number of representative training examples, often in the form of manually annotated images.
Since manual annotation is costly, our research aims at reducing the amount of required training examples and manual annotation for building object class models, thereby increasing scalability. We explore three different ways of achieving this goal.
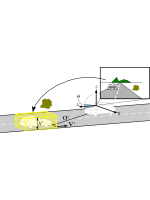
Monocular Scene Understanding from Moving Platforms
This project combines state-of-the-art object detectors, semantic scene segmentation and the notion of tracklets to perform 3D scene understanding from a moving platform with a monocular camera. Improved results are presented for pedestrians, cars and trucks.