Previous work on predicting the target of visual search from human fixations only considered closed-world settings in which training labels are available and predictions are performed for a known set of potential targets[1, 2]. In this work we go beyond the state of the art by studying search target prediction in an open-world setting in which we no longer assume that we have fixation data to train for the search targets. We present a dataset containing fixation data of 18 users searching for natural images from three image categories within synthesised image collages of about 80 images. In a closed-world baseline experiment we show that we can predict the correct target image out of a candidate set of five images. We then present a new problem formulation for search target prediction in the open-world setting that is based on learning compatibilities between fixations and potential targets.
Prediction of Search Targets From Fixations in Open-World Settings
Abstract
Download
Here you can see a sample of the gaze data. In the media name, first you can find the search image and then the collage.
Please download the full dataset here(374.9 MB (374,898,080 bytes)).
| MediaName | FixationIndex | GazeDuration | FixationX | FixationY | PupilLeft | PupilRight | |
| 0000047953-L.jpg | 161 | 340 | 115 | 47 | 2,60 | 2,68 | |
| 0000047953-L.jpg | 161 | 340 | 115 | 47 | 2,60 | 2,68 | |
| 0000047953-L.jpg | 161 | 340 | 115 | 47 | 2,61 | 2,67 | |
| 0000047953-L.jpg | 161 | 340 | 115 | 47 | 2,62 | 2,67 | |
| 0000047953-L.jpg | 161 | 340 | 115 | 47 | 2,61 | 2,67 | |
| 0000047953-L.jpg | 161 | 340 | 115 | 47 | 2,62 | 2,67 | |
| 0000047953-L.jpg | 161 | 340 | 115 | 47 | 2,63 | 2,67 | |
| 14x6-1.jpg | 215 | 133 | 401 | 1373 | 2,70 | 2,82 | |
| 14x6-1.jpg | 215 | 133 | 401 | 1373 | 2,69 | 2,73 | |
| 14x6-1.jpg | 215 | 133 | 401 | 1373 | 2,70 | 2,76 | |
The data is only to be used for non-commercial scientific purposes. If you use this dataset in scientific publication, please cite the following paper:
Data Collection and Collage Synthesis
Given the lack of an appropriate dataset, we designed a human study to collect fixation data during visual search.We opted for a task that involved searching for a single image (the target) within a synthesised collage of images (the search set). Each of the collages are the random permutation of a finite set of images.
To explore the impact of the similarity in appearance between target and search set on both fixation behaviour and automatic inference, we have created three different search tasks covering a range of similarities. In prior work, colour was found to be a particularly important cue for guiding search to targets and target-similar objects [3, 4].Therfore we have selected for the first task 78 coloured O'Reilly book covers to compose the collages. These covers show a woodcut of an animal at the top and the title of the book in a characteristic font underneath. Given that overall cover appearance was very similar, this task allows us to analyse fixation behaviour when colour is the most discriminative feature.
For the second task we use a set of 84 book covers from Amazon. In contrast to the first task, appearance of these covers is more diverse. This makes it possible to analyse fixation behaviour when both structure and colour information could be used by participants to find the target.
Finally, for the third task, we use a set of 78 mugshots from a public database of suspects.In contrast to the other tasks, we transformed the mugshots to grey-scale so that they did not contain any colour information. In this case, allows abalysis of fixation behaviour when colour information was not available at all. We found faces to be particularly interesting given the relevance of searching for faces in many practical applications. In the image below you can see a sample collage from Amazon, O'Reilly and Mugshots(left to right).

Sample image collages used for data collection: Amazon book covers (left), O'Reilly book covers (middle),mugshots (right, blurred for privacy reasons). Participants were asked to find different targets within random permutations of these collages.
Participants, Apparatus, and Procedure
We recorded fixation data of 18 participants (nine male) with different nationalities and aged between 18 and 30 years. The eyesight of nine participants was impaired but corrected with contact lenses or glasses.
To record gaze data we used a stationary Tobii TX300 eye tracker that provides binocular gaze data at a sampling frequency of 300Hz. Parameters for fixation detection were left at their defaults: fixation duration was set to 60ms while the maximum time between fixations was set to 75ms.The stimuli were shown on a 30 inch screen with a resolution of 2560x1600 pixels.Participants were randomly assigned to search for targets for one of the three stimulus types.
We first calibrated the eye tracker using a standard 9-point calibration, followed by a validation of eye tracker accuracy. After calibration, participants were shown the first out of five search targets. Participants had a maximum of 10 seconds to memorise the image and 20 seconds to subsequently find the image in the collage. Collages were displayed full screen and consisted of a fixed set of randomly ordered images on a grid.The target image always appeared only once in the collage at a random location.To determine more easily which images participants fixated on, all images were placed on a grey background and had a margin to neighbouring images of on average 18 pixels. As soon as participants found the target image they pressed a key. Afterwards they were asked whether they had found the target and how difficult the search had been. This procedure was repeated twenty times for five different targets, resulting in a total of 100 search tasks.
Content
The dataset contains three categories: "Amazon'', "O'Reilly'' and "Mugshots''. For each category, there is a folder that contains 4 subfolder: search targets, Collages, Gaze data and binary mask that we used to get the position of each individual image in the collages.
In the subfolder search targets you can find the 5 single images. The participants were looking for this image in the collages.
In the folder Collages there are 5 subfolder. Subfolder with the same name as the search target indicate that users saw those collages for the search target. There are 20 collages per search target.
In the folder gaze data you can find Media name , Fixation order, Fixation position on the screen, pupil size for left and right eye.
Method
We used fixation data to predict the users search target. We extract a a patch around each fixation. All the fixation patches enters the k-means clustering method to produce the feature vectors or visual word vectors. The created feature vectors used in our closed and open world approach to predictthe user search target.
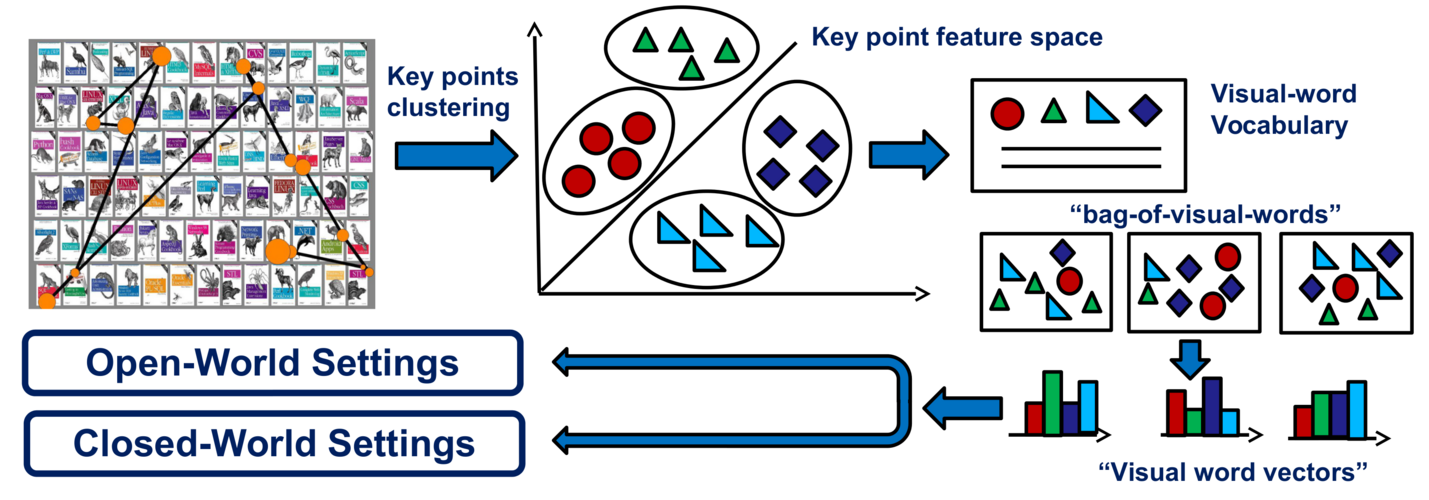
Evaluation
We show the performance of our algorithms in open and closed world approach. Here you can find our results on the close and open world approach. For the further results, please refer to our paper.
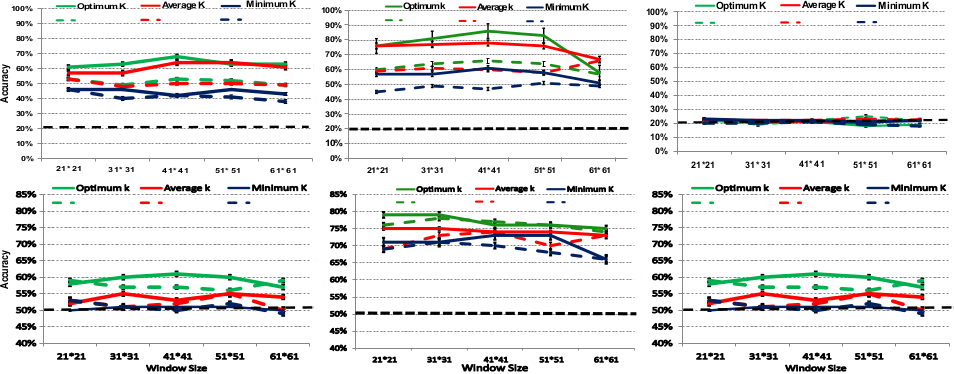
Closed-world(first row) and open-World(second row) evaluation results showing mean and standard deviation of cross-participant prediction accuracy for O'Reilly book cover (left top and bottom), Amazon book covers(middle top and bottom), and mugshots (right top and bottom). Results are shown with (straight lines) and without (dashed lines) using the proposed sampling approach around fixation locations. The chance level is indicated with the dashed line.
References
[1] A. Borji, A. Lennartz, and M. Pomplun. What do eyes reveal about the mind?: Algorithmic inference of search targets from fixations. Neurocomputing, 2014.
[2] G. J. Zelinsky, Y. Peng, and D. Samaras. Eye can read your mind: Decoding gaze fixations to reveal categorical search targets. Journal of Vision, 13(14):10, 2013.
[3] A. D. Hwang, E. C. Higgins, and M. Pomplun. A model of top-down attentional control during visual search in complex scenes. Journal of Vision, 9(5):25, 2009.
[4] B. C. Motter and E. J. Belky. The guidance of eye movements during active visual search. Vision Research, 38(12):1805–1815, 1998.