Learning Smooth Pooling Regions for Visual Recognition
Mateusz Malinowski and Mario Fritz
Abstract
Biologically inspired, from the early HMAX model to Spatial Pyramid Matching, spatial pooling has played an important role in visual recognition pipelines. By aggregating local statistics, it equips the recognition pipelines with a certain degree of robustness to translation and deformation yet preserving spatial information. Despite of its predominance in current recognition systems, we have seen little progress to fully adapt the pooling strategy to the task at hand. In this paper, we propose a flexible parameterization of the spatial pooling step and learn the pooling regions together with the classifier. We also investigate a smoothness regularization term that in conjuncture with an efficient learning scheme makes learning scalable. Our framework can work with both popular pooling operators - sum-pooling and max-pooling. Finally, we show benefits of our approach for object recognition tasks based on visual words and higher level event recognition tasks based on object-banks features. In both cases, we improve over the hand-crafted spatial pooling step showing the importance of its adaptation to the task.
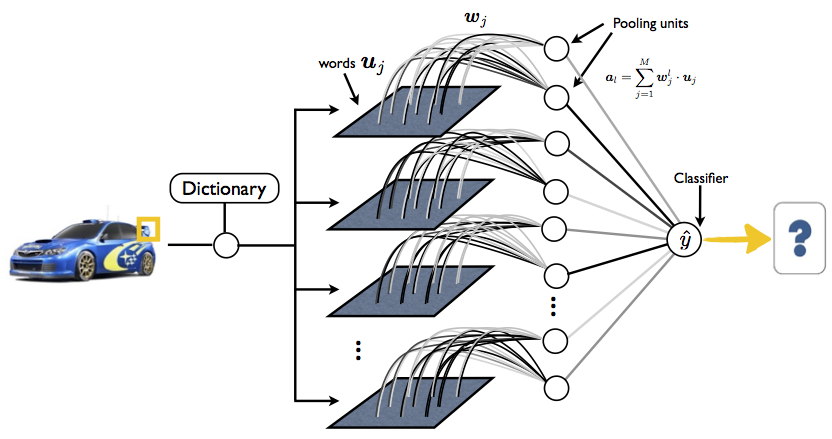
Figure 1. Sketch of our architecture. We encode the patches extracted from the images using popular encoding method. Next, we couple every position of such encoded patches with the classifier via the pooling weights. Our method learns both, the pooling weights and classifier's parameters, at the same time.
Results

Figure 2. Comparison shows Accuracy results with respect to the number of dictionary elements. From the figure, we see the improvement of our learnt spatial filters over the baseline. We also see that the advantage of spatial pooling diminishes when larger dictionaries are available. Interestingly, random spatial pooling gives quite good results - significantly outperforming the bag of features approach.
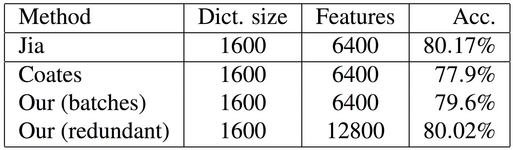
Table 1. Results on CIFAR-10.
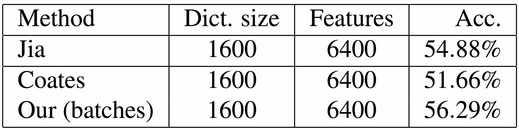
Table 2. Results on CIFAR-100.

Figure 3. Visual comparison between filters. Coates represents a traditional (hand-designed) spatial pooling approach, while l2, smooth and smooth & l2 show learnt filters when different regularization terms are used.

Source code:
The source code can be downloaded here (BMVC 2013 version).
You can also check my GitHub account for the latest version (may not be compatible with the BMVC 2013 version).
@INPROCEEDINGS{malinowski2013bmvc,
author = {Malinowski, Mateusz and Fritz, Mario},
title = {Learning Smooth Pooling Regions for Visual Recognition},
booktitle = {British Machine Vision Conference (BMVC)},
year = {2013},
month = {September}
}References
[1] Learning Smooth Pooling Regions for Visual Recognition. M. Malinowski, and M. Fritz. BMVC 2013.
[2] Learnable Pooling Regions for Image Classification . M. Malinowski, and M. Fritz. ICLR 2013: Workshop.