Generating Visual Explanations
Lisa Anne Hendricks, Zeynep Akata, Marcus Rohrbach,
Jeff Donahue, Bernt Schiele and Trevor Darrell
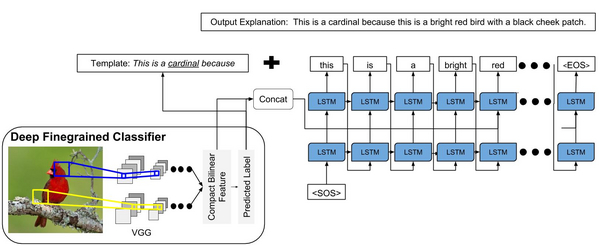
Clearly explaining a rationale for a classification decision to an end-user can be as important as the decision itself. Existing approaches for deep visual recognition are generally opaque and do not output any justification text; contemporary vision-language models can describe image content but fail to take into account class-discriminative image aspects which justify visual predictions. We propose a new model that focuses on the discriminating properties of the visible object, jointly predicts a class label, and explains why the predicted label is appropriate for the image. We propose a novel loss function based on sampling and reinforcement learning that learns to generate sentences that realize a global sentence property, such as class specificity. Our results on a fine-grained bird species classification dataset show that our model is able to generate explanations which are not only consistent with an image but also more discriminative than descriptions produced by existing captioning methods.
Paper can be found here
@inproceedings {HARDSD16,
title = {Generating Visual Explanations},
booktitle = {European Conference of Computer Vision (ECCV)},
year = {2016},
author = {Lisa Anne Hendricks and Zeynep Akata and Marcus Rohrbach and Jeff Donahue and Bernt Schiele and Trevor Darrell}
}