Dem Computer beibringen, wieviel er weiß.
Die automatisierte Wissensextraktion und -konsolidierung ist ein wichtiger Schritt zum Aufbau intelligenter und wissensbasierter Anwendungen. In großen Projekten wie NELL, DBpedia oder Yago lesen Maschinen automatisch Webinhalte und konsolidieren sie zu enzyklopädischen Darstellungen der Realität. Eine wesentliche Einschränkung dieser Wissensbasen besteht darin, dass sie keine Informationen darüber enthalten, wie viel sie tatsächlich wissen.
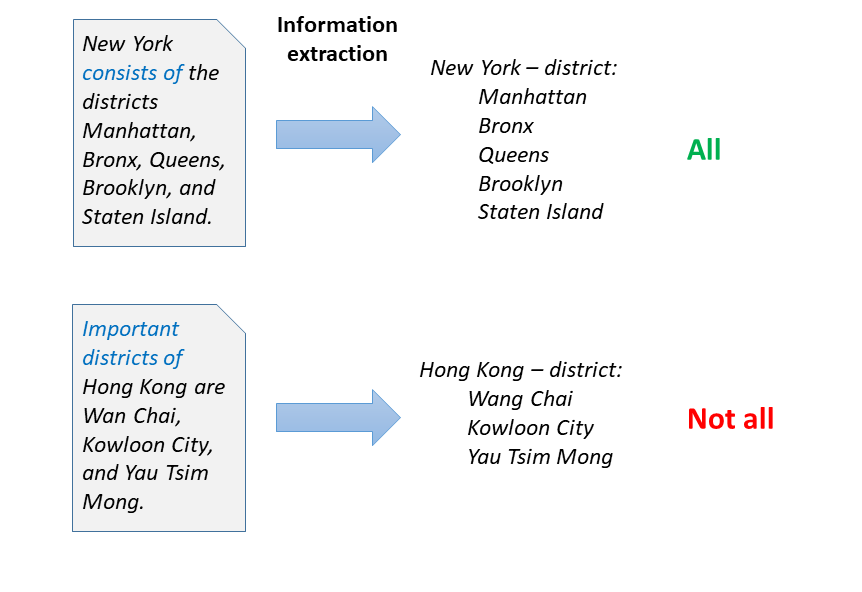
Betrachten Sie die Sätze in der Abbildung. Aus diesen beiden Sätzen können mit den Methoden der Textextraktion (NLP) leicht 5 bzw. 3 Distrikte von New York und Hongkong extrahiert werden. Würde die Maschine dann alle Distrikte kennen?
In unserer Forschung versetzen wir Maschinen in die Lage, zu verstehen, wie viel sie wissen, (i) indem wir Kardinalitätsgrenzen für Informationen ausfindig machen, (ii) indem wir linguistische Theorien der menschlichen Kommunikation zur Abschätzung der Reichweite nutzen.
Beim Data-Mining von Kardinalitätsgrenzen bauen wir Informationsextraktionsmethoden auf, die auf numerische Informationen in Texten abzielen, und verknüpfen sie mit tatsächlichen Extraktionen. Für das obige Beispiel würde ein Satz wie "Hongkong ist in 17 Distrikte unterteilt" das entscheidende Stichwort liefern: Die aufgeführten Namen repräsentieren somit 3 der 17 Distrikte. Unsere Methode stützt sich auf Algorithmen zur Sequenzmarkierung, wie CRFs und LSTMs, und kann Herausforderungen wie verzerrte Trainingsdaten, Kompositionalität ("besteht aus 5 Großstadt- und 12 ländlichen Bezirken") und hierarchische Differenzierung ("besteht aus 4 Bezirken, die weiter in 17 Distrikte und 57 Räte unterteilt sind") erfolgreich bewältigen.
Bei der Anwendung der linguistischen Kommunikationstheorien bauen wir auf Grices Maximen der kooperativen Kommunikation auf. Danach wird durch den Sprecher ein ausgewogenen Verhältnis zwischen Quantität ("sag, was du weißt") und Relevanz ("sag, was zählt") eingehalten. Daher ist der Kontext entscheidend: Ein Reiseführer kann sich natürlich auf wichtige Bezirke konzentrieren, eine enzyklopädische Beschreibung strebt danach, alle abzudecken. Um den Schwerpunkt eines Kontexts zu identifizieren, bauen wir Textklassifikatoren auf, welche Auslösewörter und Themen erkennen, die die Abdeckung von Texten in Richtung bestimmter Beziehungen anzeigen. In den Beispielen sind wichtige Auslösewörter "wichtige Bezirke" (also wahrscheinlich nicht alle) und "besteht aus" (ein Begriff, der typischerweise vor vollständigen Aufzählungen verwendet wird). Unsere Modelle können die Abdeckung verschiedener Beziehungen wie "Bezirk", "Teil von" (von Kunstwerken), "Kind" oder "Mitglied von" (von Bands) erfolgreich abschätzen.
Beide Ansätze ergänzen sich und ermöglichen Maschinen, die ein Verständnis für die Stärken und Grenzen ihres Wissens haben. Dieses Verständnis ist sowohl bei Anwendungen wie der Beantwortung von Fragen (wobei Maschinen darauf hinweisen sollten, wenn sie sich einer Antwort nicht sicher sind) als auch bei der automatisierten Konstruktion der Wissensbasis selbst wichtig, bei der es nur mit dem Bewusstsein von Lücken möglich ist, weitere Extraktionsbemühungen richtig zu fokussieren.
