STD2P: RGBD Semantic Segmentation Using Spatio-Temporal Data-Driven Pooling

Figure 1: Pipeline of the proposed method. Our multi-view semantic segmentation network is built on top of a CNN. It takes a RGBD sequence as input and computes the semantic segmentation of a target frame with the help of unlabeled frames. We use superpixels and optical flow to establish region correspondences, and fuse the posterior from multiple views with the proposed Spatio-Temporal Data-Driven Pooling (STD2P).
Yang He, Wei-Chen Chiu, Margret Keuper and Mario Fritz
Abstract
In this project, we propose a novel superpixel-based multi-view convolutional neural network for semantic image segmentation. The proposed network produces a high quality segmentation of a single image by leveraging information from additional views of the same scene. Particularly in indoor videos such as captured by robotic platforms or handheld and bodyworn RGBD cameras, nearby video frames provide diverse viewpoints and additional context of objects and scenes. To leverage such information, we first compute region correspondences by optical flow and image boundary-based superpixels. Given these region correspondences, we propose a novel spatio-temporal pooling layer to aggregate information over space and time. We evaluate our approach on NYU-Depth-V2 and the SUN3D datasets and compare it to various state-of-the-art single-view and multi-view approaches. Besides a general improvement over the state-of-the-art, we also show the benefits of making use of unlabeled frames during training for multi-view as well as single-view prediction.
Results
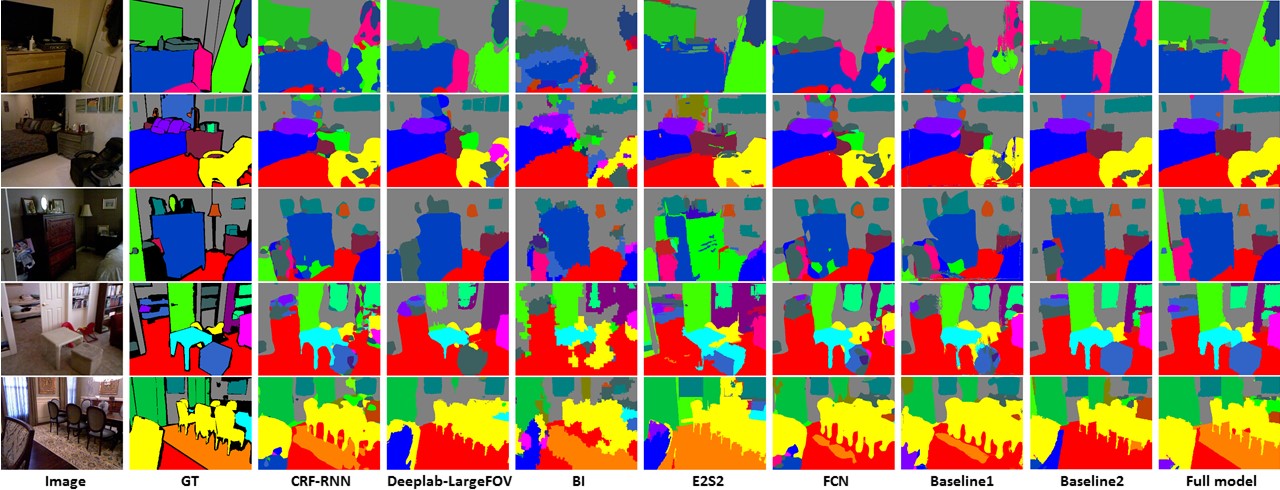
Figure 2: Visualization examples on NYUDv2 dataset.

Figure 3: Visualization examples on SUN3D dataset.
Download
Arxiv, Paper, Supplementary Material, Poster
Pretrained model, superpixel and optical flow
Feel free to contact Yang He, if you have any questions.
Reference
- Yang He, Wei-Chen Chiu, Margret Keuper, Mario Fritz, STD2P: RGBD Semantic Segmentation Using Spatio-Temporal Data-Driven Poolin, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
If our work is useful for your research, please consider citing:
@inproceedings{yang_cvpr17,
title={STD2P: RGBD Semantic Segmentation Using Spatio-Temporal Data-Driven Pooling},
author={Yang He and Wei-Chen Chiu and Margret Keuper and Mario Fritz},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2017}}