Distributed Algorithms for Fault-tolerant Hardware
Christoph Lenzen
Distributed Algorithms for Fault-tolerant Hardware
Distributed Computing is concerned with systems in which communication – as opposed to computation – is the main obstacle to solving a given task fast. It also addresses the issue of fault-tolerance, i.e., the ability of a system to work correctly even if some of its components fail. As hardware development continues to follow “Moore’s Law” which states that the number of basic component in off-the-shelf hardware doubles roughly every 18 months, both of these aspects become increasingly important. In other words, nowadays a common computer chip, and even more so a multi-core processor, is a distributed system in its own right.
If this claim strikes you as odd, just consider the following facts: (i) at today’s clock speeds in the gigahertz range, an electrical signal cannot traverse an entire chip in a single clock cycle; (ii) by now, standard processors host billions of transistors, making it virtually impossible to guarantee that each of them operates correctly; and (iii) the most basic standard components of computer chips have reached a size of about 10-20 nanometers (a nanometer is a billionth of a meter!), a size at which physical effects necessitate dealing with transient faults, i.e., components temporarily and unpredictably operating out-of-spec.
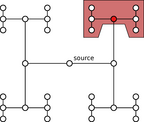
Figure1: Clock tree. In case of a fault at the junction marked red the entire red area fails.
One of the most fundamental challenges in designing computer chips is the distribution of a well-behaved clock signal throughout the chip. Up to a certain scale, this can be successfully achieved by so-called clock trees [see figure 1] . Basically, a clock tree is carefully engineered to ensure that the clock signal generated by a single quartz crystal arrives at adjacent components at (almost) the same time. This permits to perform computations synchronously: a computational step is executed, then the results are “locked” and communicated, and then the received new values are used for the next computational step. The synchronous design paradigm offers many advantages and is therefore the de facto standard in hardware design – up to the point at which systems become too large to be efficiently clocked by a single clock tree.
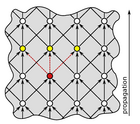
Figure 2: Part of a clock distribution grid. Each node waits for the second received signal before forwarding the clock signal on all outgoing links. Hence, the yellow nodes still operate correctly even if the red node or its outgoing links fail.
We argue that using distributed algorithms, one can efficiently and reliably generate and distribute a clock signal on a significantly larger scale than possible with a single clock tree. For instance, consider Figure 2, which illustrates a simple fault-tolerant clock distribution mechanism. In contrast to a clock tree, there are different paths along which the clock signal is propagated; hence, the system as a whole can still operate correctly even if a few isolated nodes or links fail. We work towards efficient realizations of this and similar schemes to enable building larger, yet more reliable systems.

Christoph Lenzen
DEPT. 1 Algorithms and Complexity
Phone +49 681 9325-1008
Email: clenzen@mpi-inf.mpg.de